

설치 매뉴얼
AWS 설정
먼저 AWS 웹 콘솔에서 로그프레소 소나 연동에 필요한 환경을 구성하세요.
네트워크 설정
로그프레소 서버를 폐쇄망 환경에 운영하면서 AWS 클라우드와 통신을 수행해야 하는 경우, AWS Private Endpoint 구성이 필요합니다. 로그프레소 서버를 폐쇄망에서 운영하지 않는 경우, 이 과정을 생략할 수 있습니다.
가정사항
- Private Endpoint 설정은 IPSEC 터널 및 전용 사설망(Private Network) 구성이 이미 완료되어 있는 환경을 전제로 작성되었습니다. 해당 인프라가 아직 구성되지 않은 경우, 별도의 네트워크 설계 및 구축이 선행되어야 합니다.
- 본 문서에 기술된 환경 구성 방식은 일반적인 AWS 계정 구조와 네트워크 구성 기준을 기반으로 작성되었습니다.
- 고객사의 AWS 조직 구조에 따라 일부 항목은 수정되거나 추가적인 조정이 필요할 수 있습니다.
Private Endpoint 설정
-
엔드포인트 서비스 화면에서 엔드포인트 생성을 클릭하세요.
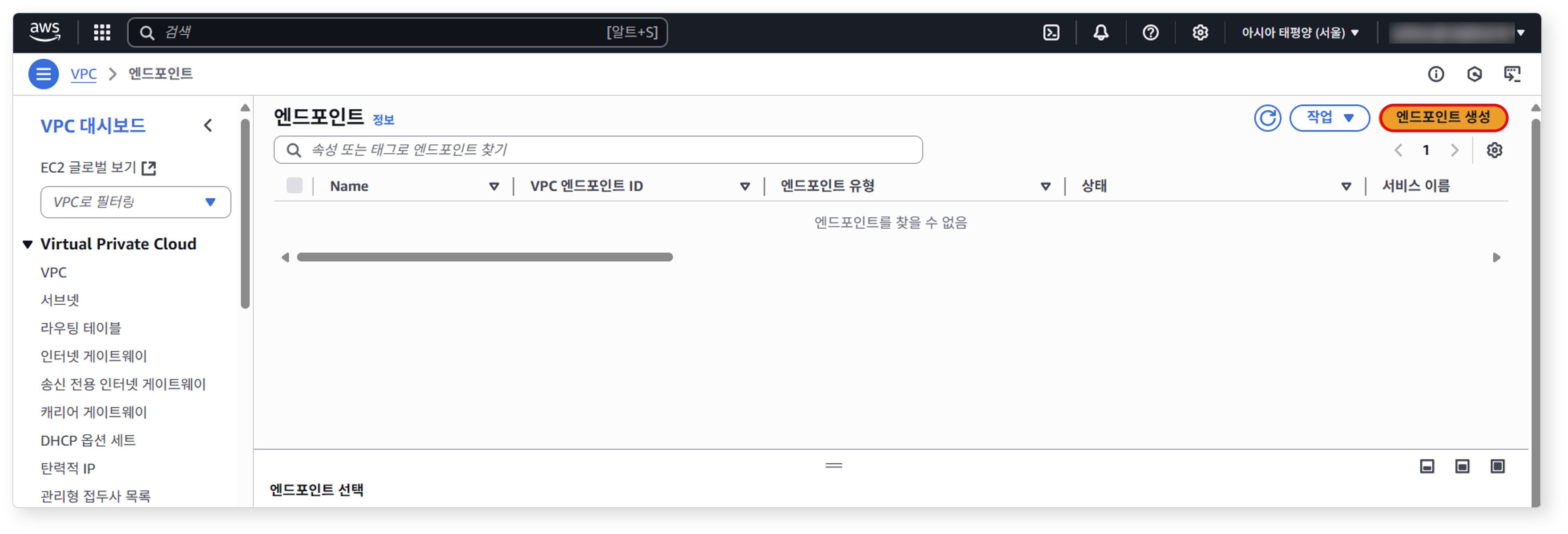
-
엔드포인트 생성 화면에서 엔트포인트 설정에 필요한 항목을 선택/입력하고 화면 하단에서 엔드포인트 생성을 클릭하세요.
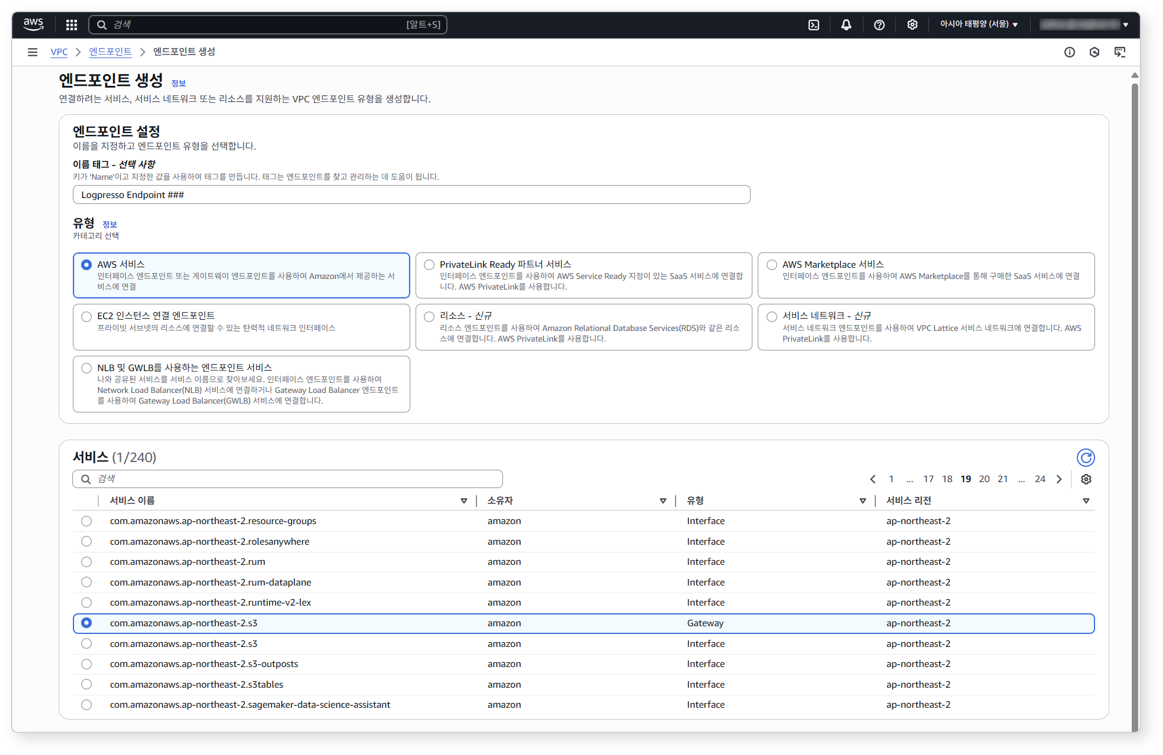
-
유형으로 AWS 서비스를 선택하세요.
-
서비스에서 다음과 같이 필요한 서비스를 선택하세요.
서비스 수집하고자 하는 AWS 서비스 com.amazonaws.ap-northeast-2.s3 AWS ALB, CloudTrail, GuardDuty, WAF com.amazonaws.ap-northeast-2.monitoring AWS Shield (CloudWatch) com.amazonaws.ap-northeast-2.sts STS (하단 Note 참고) -
VPC 및 보안 그룹은 고객사 내부망 Private Link 설정 시 구성한 항목으로 설정하세요.
Notecom.amazonaws.ap-northeast-2.sts은 로그프레소 소나 서버가 임시 자격 증명(STS)을 이용해 AWS 서비스에 접근하는 경우에만 사용됩니다. STS를 사용하지 않는 경우 생략하세요.
-
-
생성된 엔드포인트를 확인하세요.
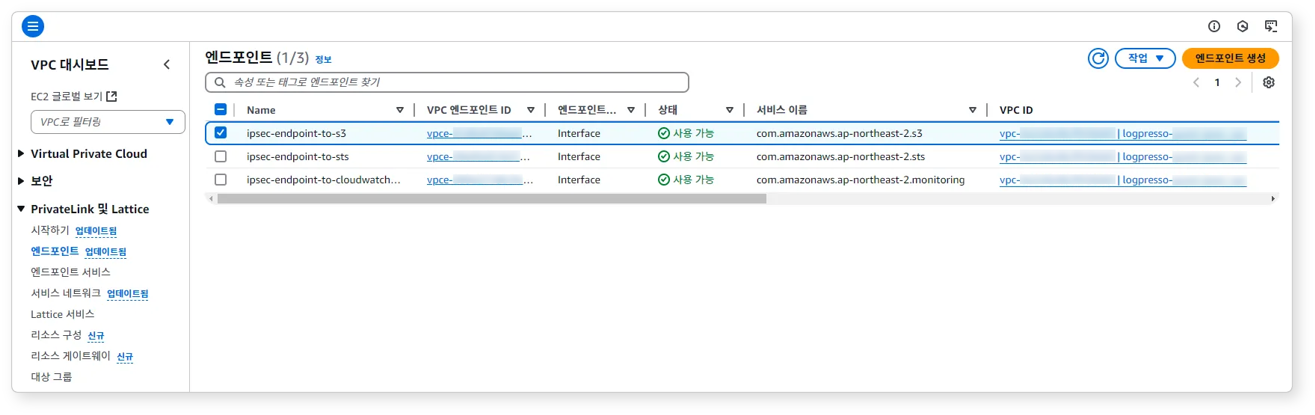
-
생성된 엔드포인트 항목 별 DNS 이름을 확인하세요. DNS 이름은 접속 프로파일을 구성할 때 사용됩니다.
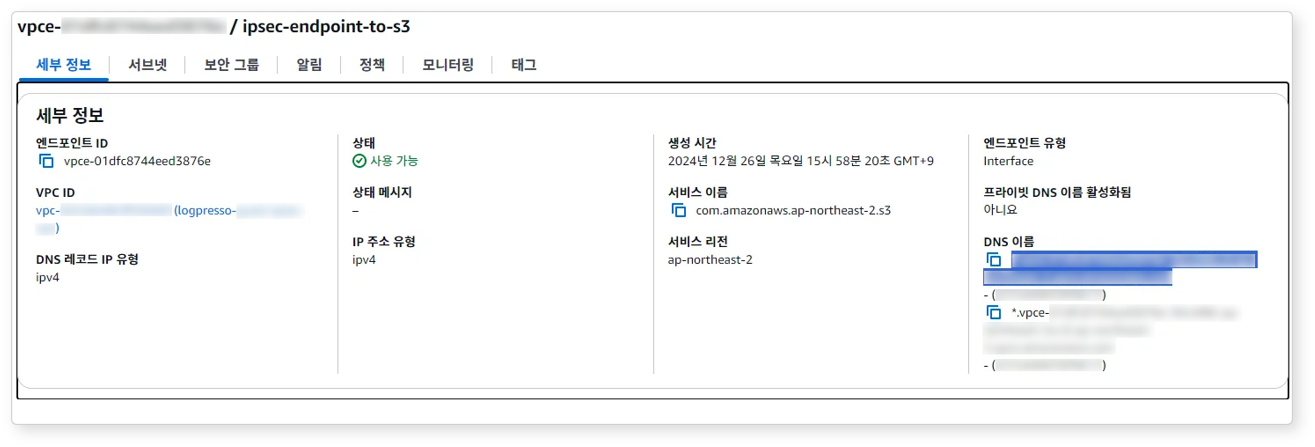
엔드포인트는 다음과 같은 형식으로 표시됩니다.
- S3:
*.vpce-***************.s3.ap-northeast-2.vpce.amazonaws.com - CloudWatch:
vpce-***************.monitoring.ap-northeast-2.vpce.amazonaws.com - STS:
vpce-***************.sts.ap-northeast-2.vpce.amazonaws.com
- S3:
IAM 정책 설정
로그프레소 소나가 AWS API를 이용해 AWS 서비스를 이용하려면 정책을 설정해야 합니다.
정책 JSON 입력
- IAM 서비스 화면에서 아래 JSON 파일을 복사하여 IAM 정책을 생성하세요. 아래 정책은 읽기 전용 권한만 존재하지만 대상이 전체 리소스로 되어있으므로, 로그프레소가 읽기 가능한 클라우드 리소스 범위를 제한하시기 바랍니다. 사용하지 않는 권한은 삭제하셔도 됩니다.
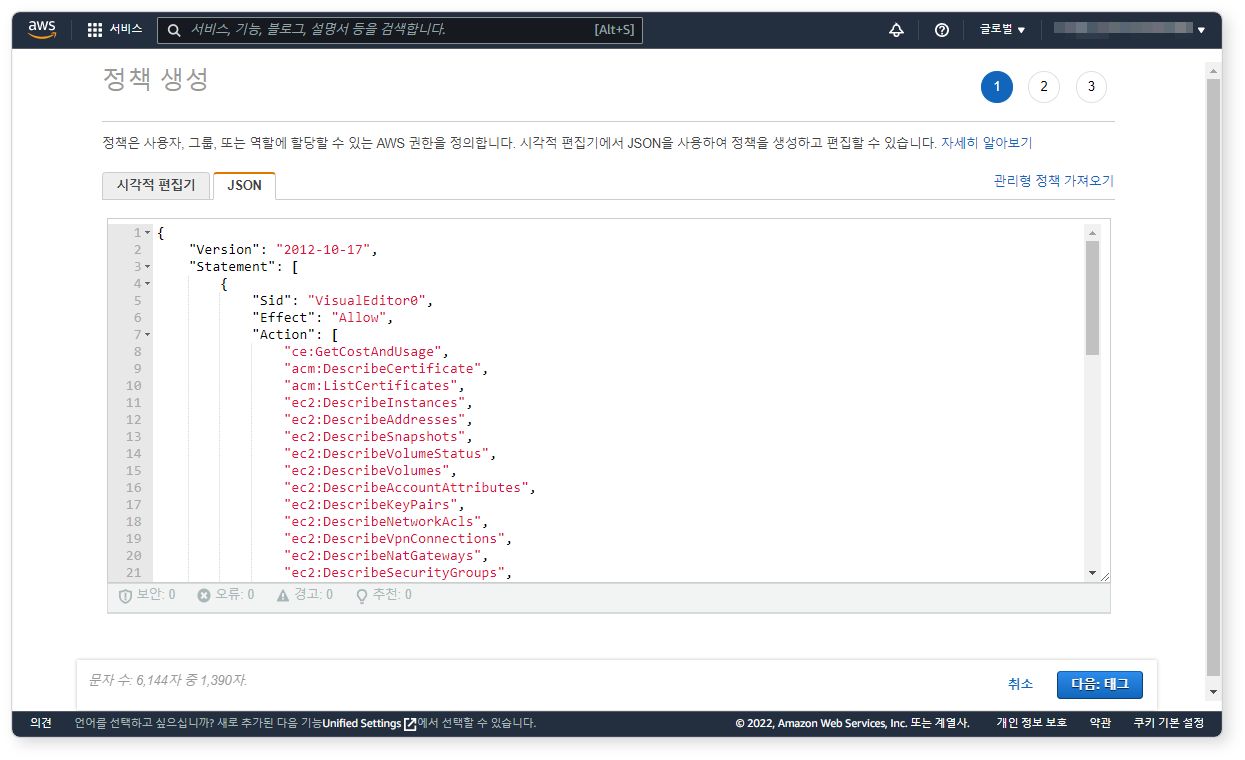
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ce:GetCostAndUsage",
"acm:DescribeCertificate",
"acm:ListCertificates",
"ec2:DescribeVpcs",
"ec2:DescribeInstances",
"ec2:DescribeAddresses",
"ec2:DescribeSnapshots",
"ec2:DescribeVolumeStatus",
"ec2:DescribeVolumes",
"ec2:DescribeAccountAttributes",
"ec2:DescribeKeyPairs",
"ec2:DescribeNetworkAcls",
"ec2:DescribeVpnConnections",
"ec2:DescribeNatGateways",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSubnets",
"ec2:DescribeRouteTables",
"ec2:DescribeInstanceStatus",
"ec2:DescribeImages",
"autoscaling:DescribeAutoScalingGroups",
"cloudwatch:GetMetricData",
"cloudwatch:ListMetrics",
"logs:DescribeLogGroups",
"iam:ListPolicies",
"iam:ListRoles",
"iam:ListUsers",
"iam:ListMFADevices",
"iam:ListAccessKeys",
"iam:GenerateCredentialReport",
"iam:GetCredentialReport",
"iam:ListVirtualMFADevices",
"iam:ListServerCertificates",
"elasticbeanstalk:DescribeEnvironments",
"elasticbeanstalk:DescribeInstancesHealth",
"elasticbeanstalk:DescribeApplications",
"elasticloadbalancing:DescribeLoadBalancers",
"elasticloadbalancing:DescribeTargetHealth",
"elasticloadbalancing:DescribeLoadBalancerAttributes",
"elasticloadbalancing:DescribeTargetGroups",
"rds:DescribeEvents",
"rds:DescribeDBLogFiles",
"rds:DownloadDBLogFilePortion",
"s3:ListAllMyBuckets",
"s3:ListBucket",
"s3:GetObject",
"s3:GetBucketAcl",
"s3:GetBucketLocation",
"route53:ListHostedZones",
"wafv2:GetIPSet",
"wafv2:ListIPSets",
"wafv2:UpdateIPSet"
],
"Resource": "*"
}
]
}
WAF 쿼리 명령어를 사용하거나 차단 연동 기능을 사용하려면 아래 권한이 추가로 필요합니다:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"wafv2:GetIPSet",
"wafv2:ListIPSets",
"wafv2:UpdateIPSet"
],
"Resource": "*"
}
]
}
ECR 쿼리 명령어를 사용하려면 아래 권한이 추가로 필요합니다:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ecr:DescribeImageScanFindings",
"ecr:DescribeRegistry",
"ecr:GetAuthorizationToken",
"ecr:ListImages",
"ecr:GetRegistryScanningConfiguration",
"ecr:BatchGetImage",
"ecr:DescribeImages",
"ecr:DescribeRepositories",
"ecr:GetRepositoryPolicy",
"inspector2:ListCoverageStatistics",
"inspector2:ListFindings",
"inspector2:ListFindingAggregations",
"inspector2:ListCoverage",
"inspector2:GetFindingsReportStatus",
"inspector:ListFindings",
"inspector:DescribeFindings"
],
"Resource": "*"
}
]
}
정책 태그 추가
태그는 필요한 경우에만 설정하고 그냥 건너뛰어도 됩니다.
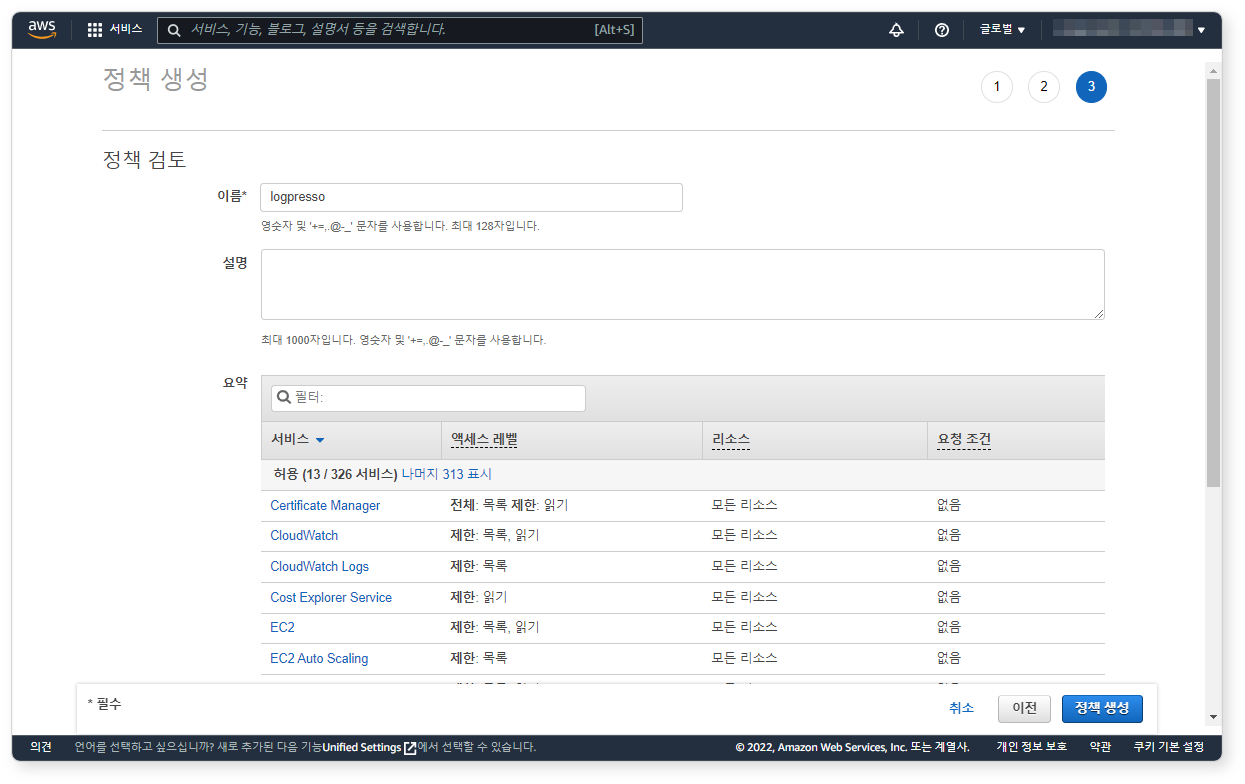
정책 검토
JSON에 따라 읽기 전용으로 정책이 구성된 것을 확인하고 정책 생성을 클릭하세요.
접근 권한 부여
로그프레소 소나가 IAM 정책에 따라 AWS API를 호출하려면 IAM 계정을 생성하거나, 임시 자격 증명(STS)을 이용해야 합니다. 두 가지 방법 중 하나를 선택하세요.
방법 1: IAM 계정 설정
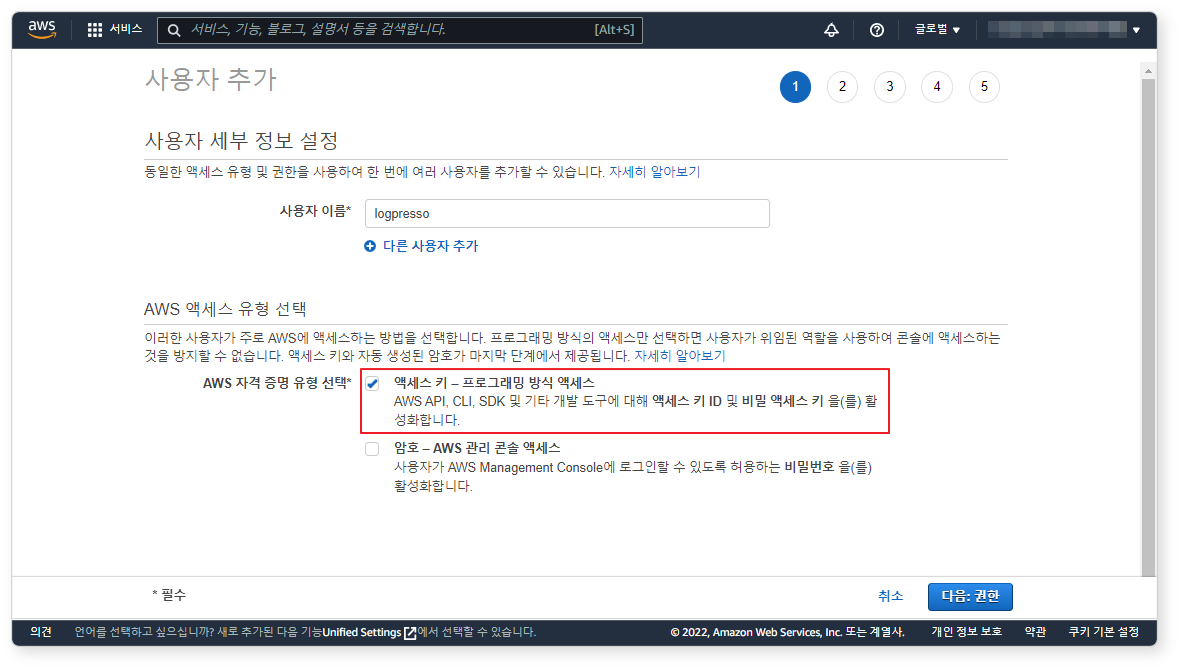
-
로그인이 요구되지 않는 사용자이므로 액세스 키 - 프로그래밍 방식 액세스를 선택하고 다음: 권한 버튼을 클릭하세요.
-
기존 정책 직접 연결을 클릭하고 방금 생성한
logpresso정책을 선택한 후 다음: 태그 버튼을 클릭하세요.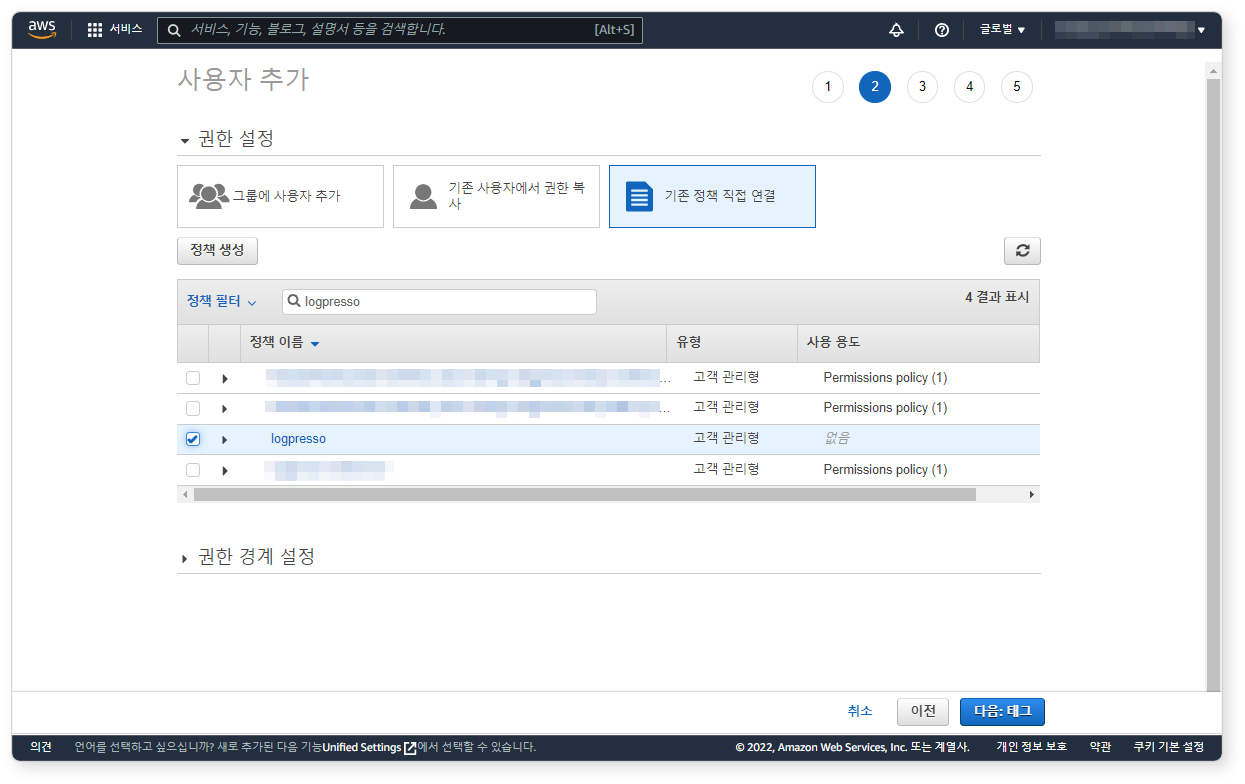
-
태그는 필요한 경우에만 설정하고 그냥 건너뛰어도 됩니다.
-
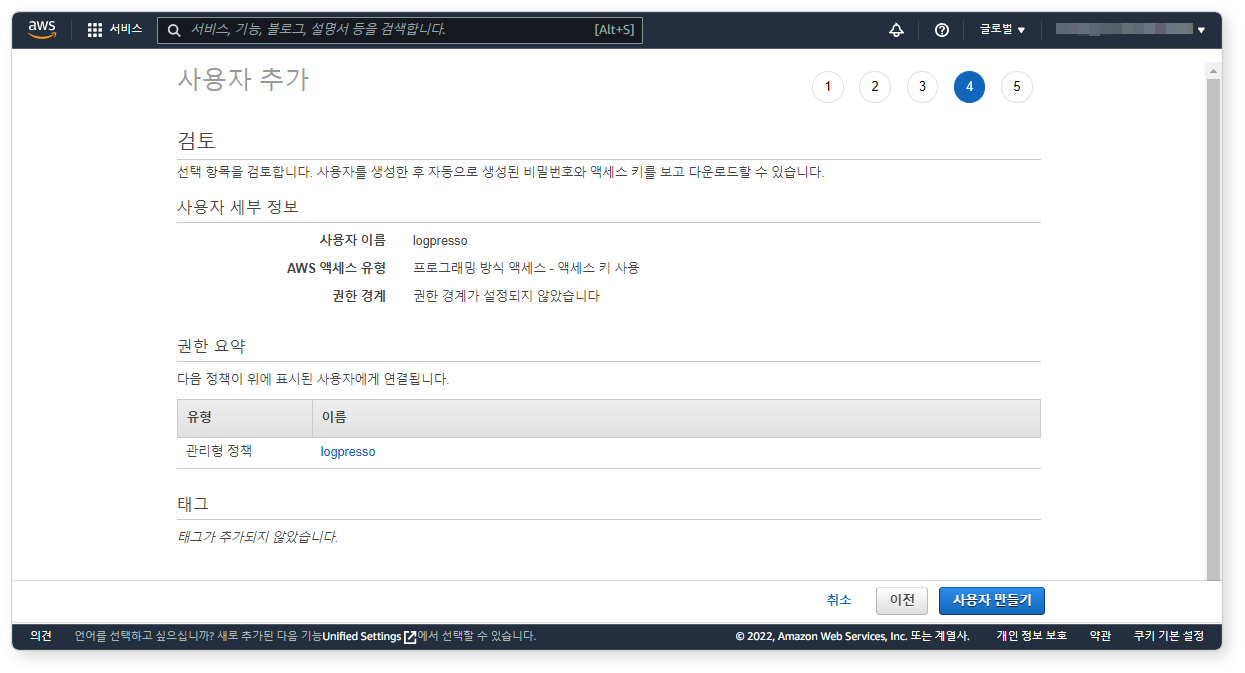
설정 내역을 확인하고 사용자 만들기 버튼을 클릭하세요.
-
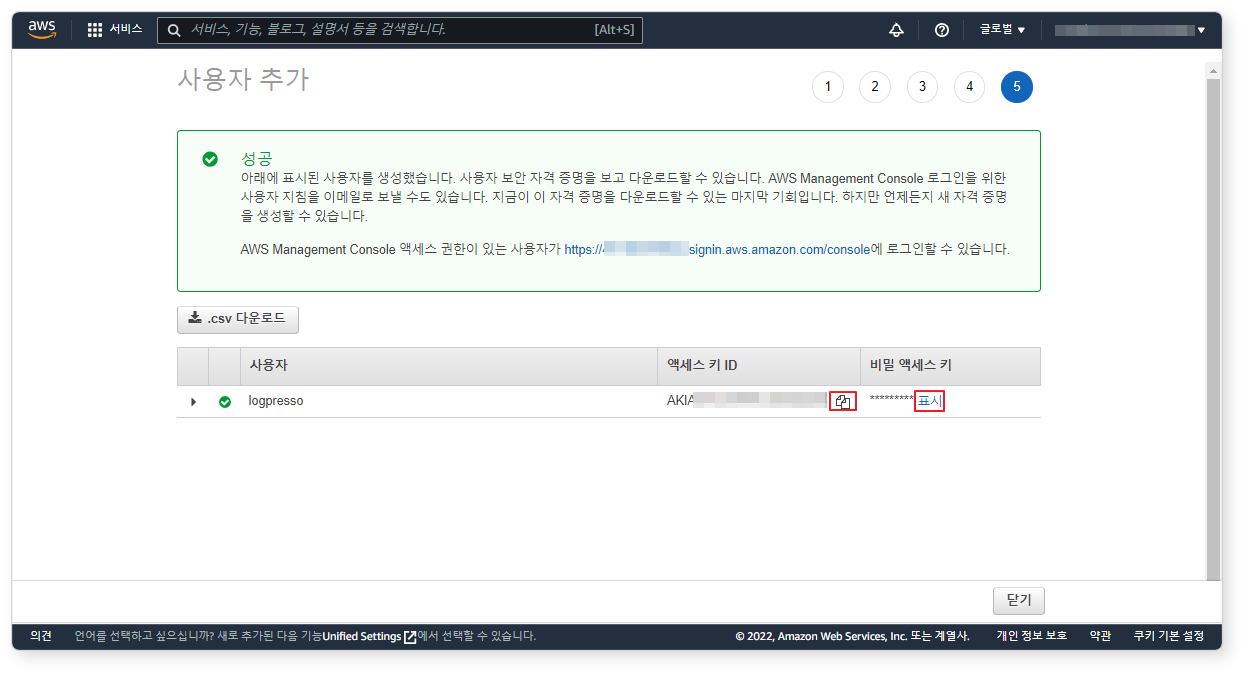
액세스 키 ID와 비밀 액세스 키를 복사하여 안전한 곳에 보관합니다. 이 단계를 지나가면 비밀 액세스 키를 확인할 수 없으므로 주의하세요.
방법 2: STS 설정
-
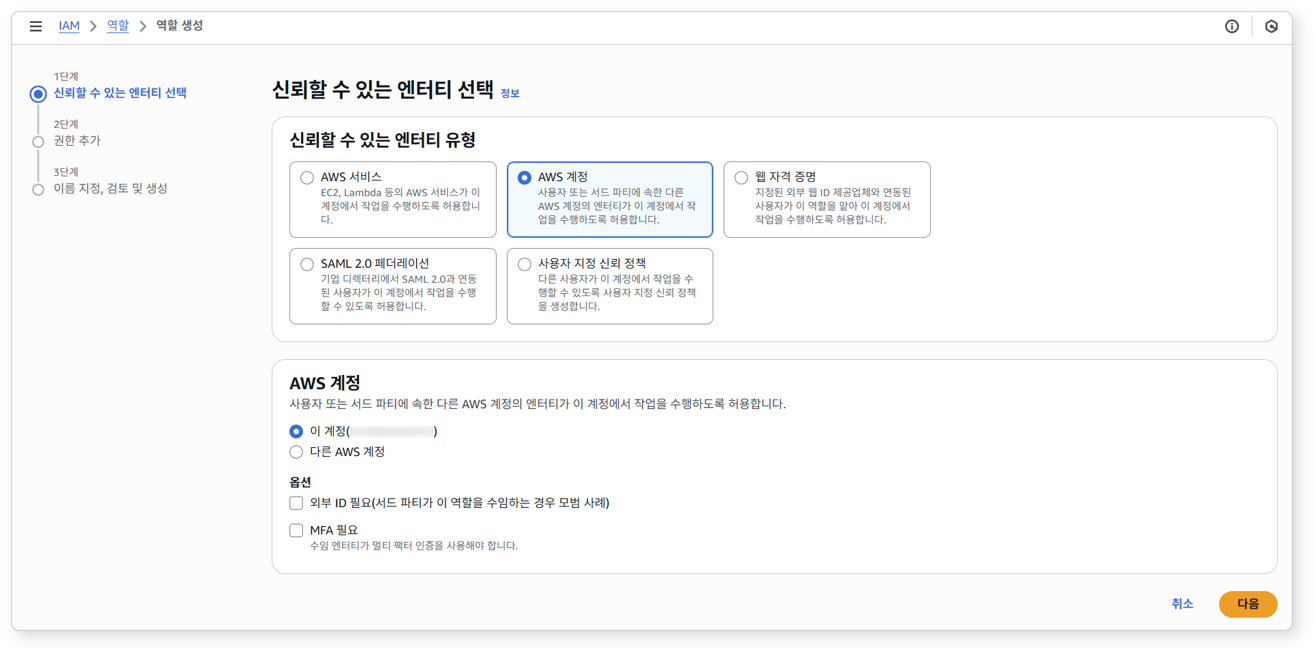
AWS 콘솔에서 IAM > 역할 면에서 역할 생성을 클릭하세요.
-
신뢰할 수 있는 엔터티 유형에서 AWS 계정을 선택하세요.
-
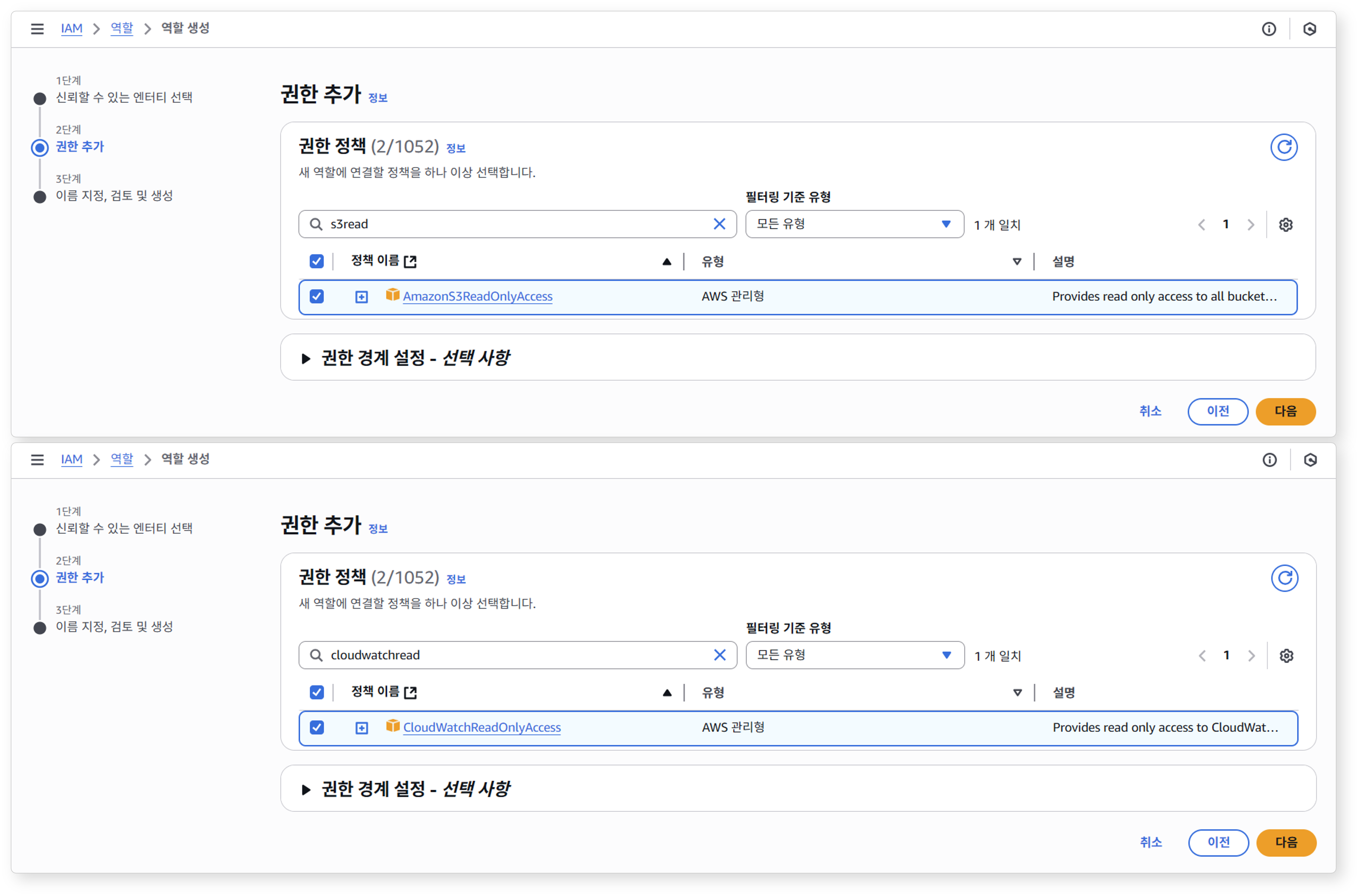
권한 추가 부분에서 STS를 통해 부여 할 권한을 선택합니다. (본 예시에서는 S3, CloudWatch 에 대한 읽기 권한을 부여합니다.)
-
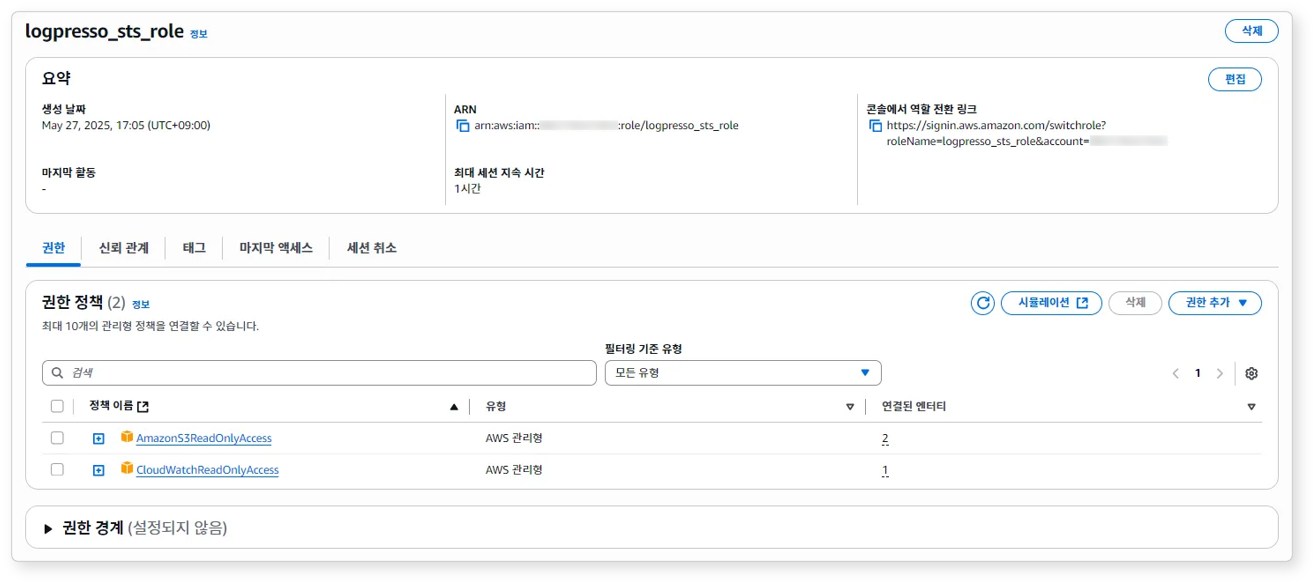
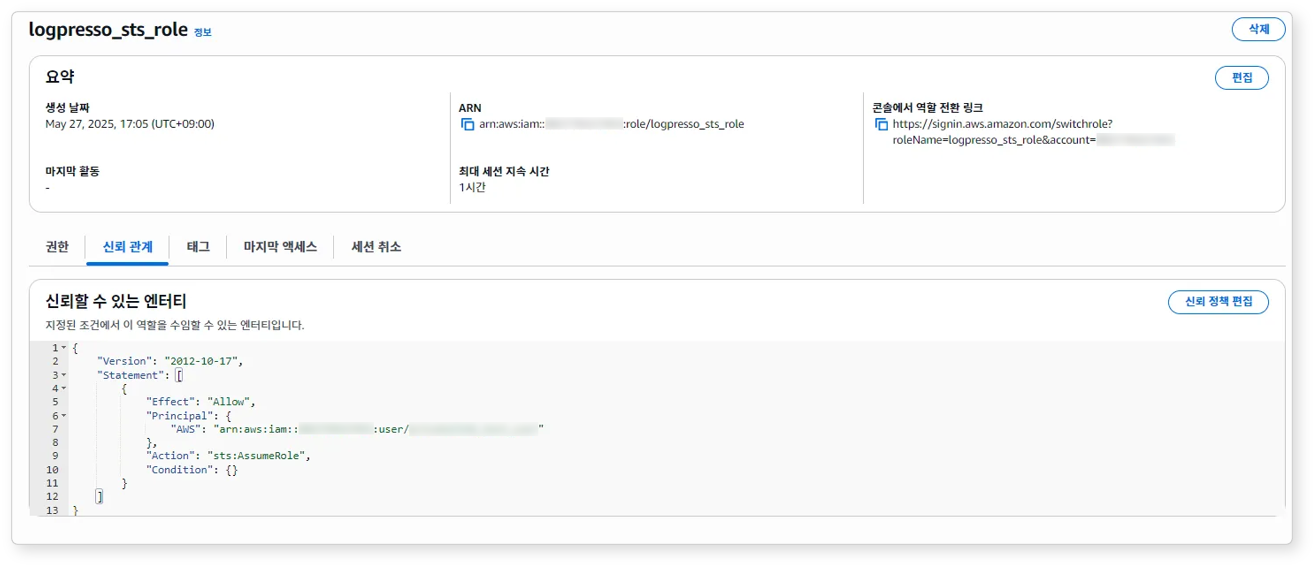
생성된 역할의 권한과 신뢰 관계를 확인하세요.
-
역할의 권한
-
역할의 신뢰 관계
-
-
생성된 STS 역할에 대한 ARN 값을 확인하세요(예:
arn:aws:iam::123456789012:role/logpresso_sts_role). 이 값은 접속 프로파일을 구성할 때 사용됩니다.
AWS Aurora 로그 수집 환경 구성
SQS 대기열 생성
유형, 이름, 액세스 정책은 다음에 열거된 값으로 사용하세요. 나머지 옵션은 기본값을 사용하거나, 운영 환경에 맞게 선택하세요.
-
유형:
FIFO선택 -
이름:
logpresso-aws-aurora-das.fifo입력 -
액세스 정책:
고급선택 후 다음 액세스 정책을 참고하여 설정(REGION, ACCOUNT_ID를 환경에 맞게 수정){ "Version": "2012-10-17", "Id": "__default_policy_ID", "Statement": [ { "Sid": "__owner_statement", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::ACCOUNT_ID:root" }, "Action": "SQS:*", "Resource": "arn:aws:sqs:REGION:ACCOUNT_ID:logpresso-aws-aurora-das.fifo" }, { "Sid": "__receiver_statement", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::ACCOUNT_ID:user/logpresso" }, "Action": [ "SQS:ChangeMessageVisibility", "SQS:DeleteMessage", "SQS:ReceiveMessage" ], "Resource": "arn:aws:sqs:REGION:ACCOUNT_ID:logpresso-aws-aurora-das.fifo" } ] }
SQS 대기열 생성 직후 화면은 아래와 같습니다.
Lambda 함수 생성
Lambda 서비스 화면에서 함수를 생성하세요. 이 함수는 S3에 로그 파일이 저장될 때마다 호출되어 SQS 대기열에 로그를 적재합니다.
-
함수 생성 방법은 새로 작성을 선택하고 기본 정보 옵션을 다음과 같이 입력하고 함수 생성 버튼을 클릭하세요. 여기에 명시되지 않은 다른 옵션들은 기본값을 사용하거나, 운영 환경에 맞게 선택하세요.
-
함수 이름:
logpresso-aws-aurora-das-log-producer입력 -
런타임: Python 3.12
-
-
함수 생성 직후 화면은 아래와 같습니다.
코드 탭 화면에서 lambda_function.py의 내용을 다음 코드로 대체해야 합니다. 이때 변수
sqs_queue_url에 할당된 문자열을 SQS 대기열logpresso-aws-aurora-das.fifo의 URL로 수정하세요.import json import boto3 import gzip s3_client = boto3.client('s3') sqs_client = boto3.client('sqs') sqs_queue_url = 'https://sqs.REGION.amazonaws.com/ACCOUNT_ID/QUEUE' def lambda_handler(event, context): # process_s3_object('BUCKET_NAME', 'FILE_NAME') for record in event['Records']: bucket_name = record['s3']['bucket']['name'] object_key = record['s3']['object']['key'] process_s3_object(bucket_name, object_key) return { 'statusCode': 200, 'body': json.dumps('Completed') } def process_s3_object(bucket_name, object_key): response = s3_client.get_object(Bucket=bucket_name, Key=object_key) data = gzip.decompress(response['Body'].read()).decode('utf-8') lines = data.splitlines() filtered = [] i = 0 for line in lines: try: i = i + 1 log_entry = json.loads(line) # NOTE: Add your own filtering condition below if 'type' in log_entry: filtered.append(json.dumps(log_entry)) except: print('error object key ' + object_key + ' row #' + str(i)) continue dup_id = 0 if filtered: max_message_size = 128 * 1024 # 128KB current_message = [] current_size = 0 for log in filtered: log_size = len(log.encode('utf-8')) + 1 if current_size + log_size > max_message_size: send_message_to_sqs(sqs_queue_url, "\n".join(current_message), object_key, dup_id) dup_id = dup_id + 1 current_message = [log] current_size = log_size else: current_message.append(log) current_size += log_size if current_message: send_message_to_sqs(sqs_queue_url, "\n".join(current_message), object_key, dup_id) dup_id = dup_id + 1 def send_message_to_sqs(queue_url, message_body, object_key, dup_id): message_group_id = 'logpresso' message_deduplication_id = object_key.split('/')[-1] response = sqs_client.send_message( QueueUrl=queue_url, MessageBody=message_body, MessageGroupId=message_group_id, MessageDeduplicationId=object_key + str(dup_id) ) print(response) return response
가상 이벤트 테스트
Lambda 함수가 정상적으로 동작하는지 시험합니다. Test 버튼을 클릭하고 아래와 같이 가상 이벤트를 편집하세요.
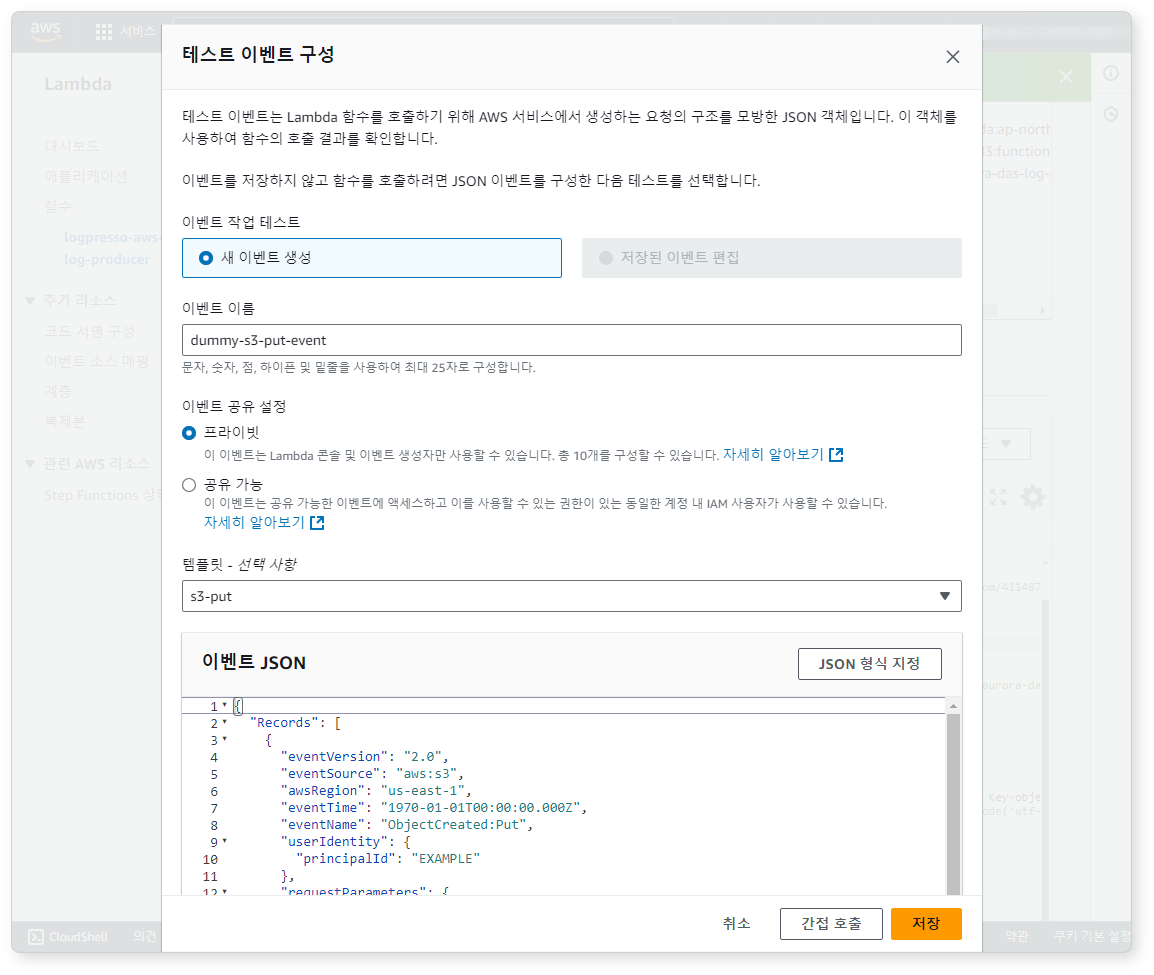
간접 호출 버튼을 클릭해서 테스트가 잘 실행되는지 확인하세요.
Lambda 인라인 정책
테스트가 잘 실행되었다면 Lambda 함수가 S3 서비스에 접근할 수 있도록 권한을 부여하세요.
-
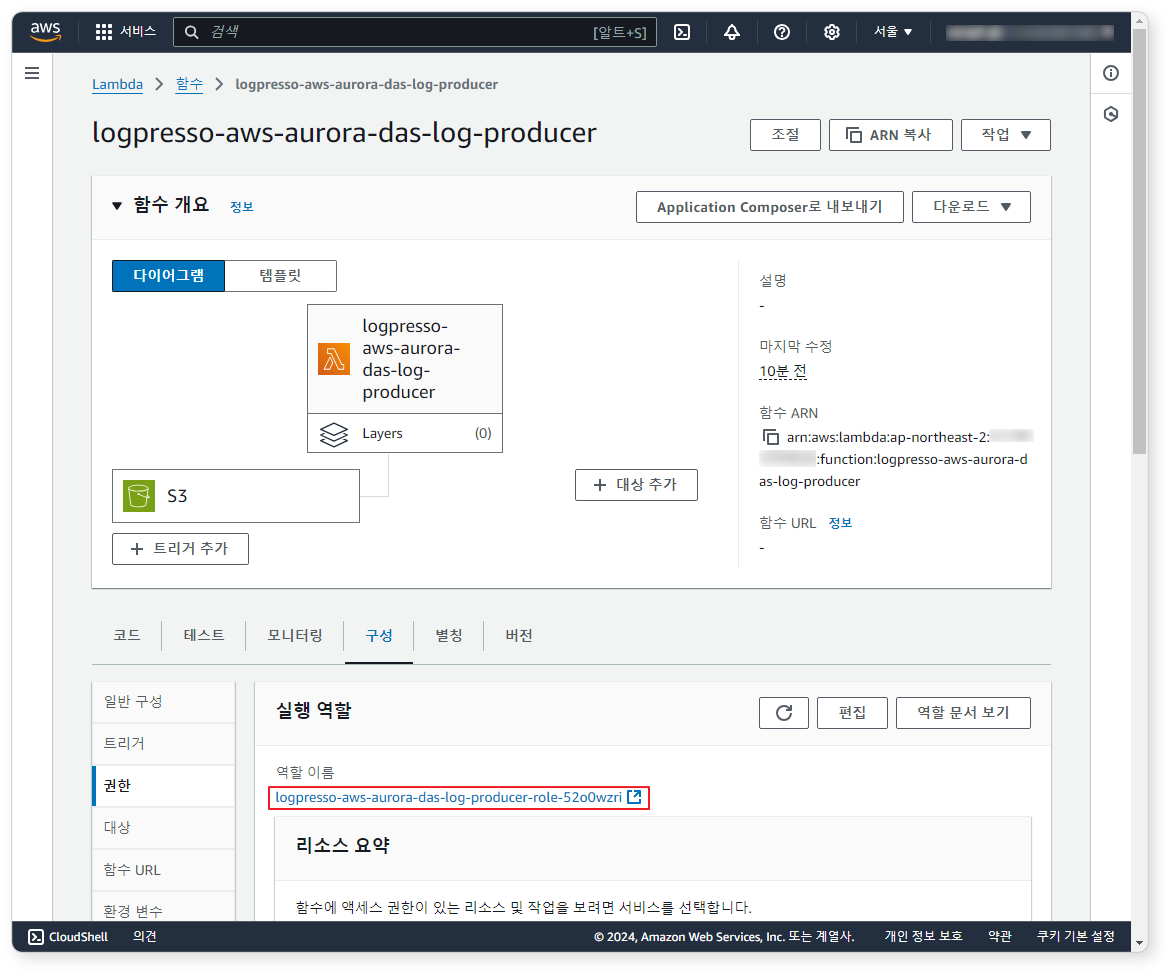
구성 탭 화면에서 역할 이름을 클릭하세요. 화면이 IAM 서비스로 이동됩니다.
-
IAM 역할 화면에서 권한 추가 > 인라인 정책 생성 버튼을 클릭하세요.
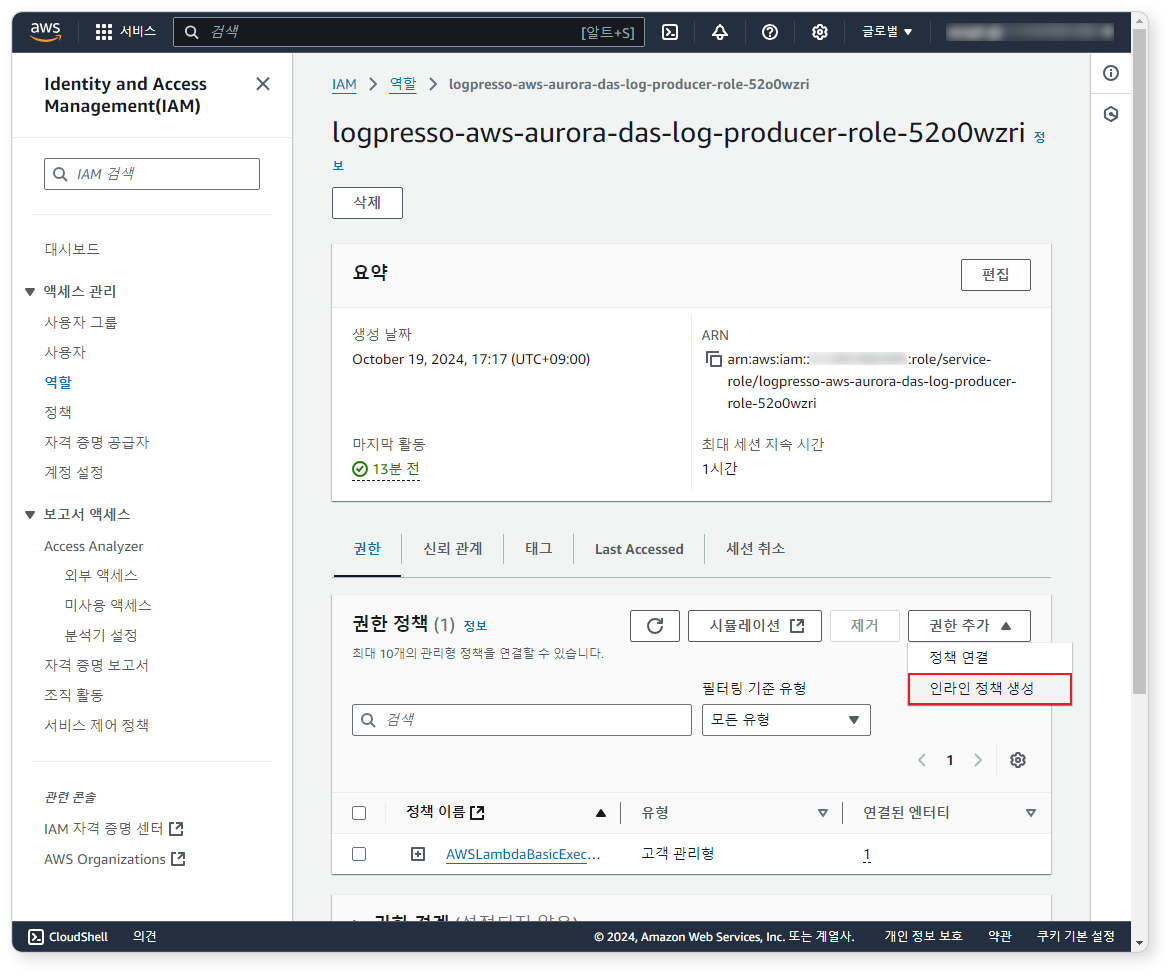
-
정책 에디터 화면에 아래 JSON 파일을 복사하여 IAM 정책을 생성하세요(REGION, ACCOUNT_ID, BUCKET_NAME, QUEUE를 환경에 맞게 수정).
Lambda 함수 트리거 추가
이제 함수 트리거를 추가합니다. S3에 로그 파일이 저장될 때마다 lambda 함수가 호출되도록 트리거 조건을 추가하세요.
-
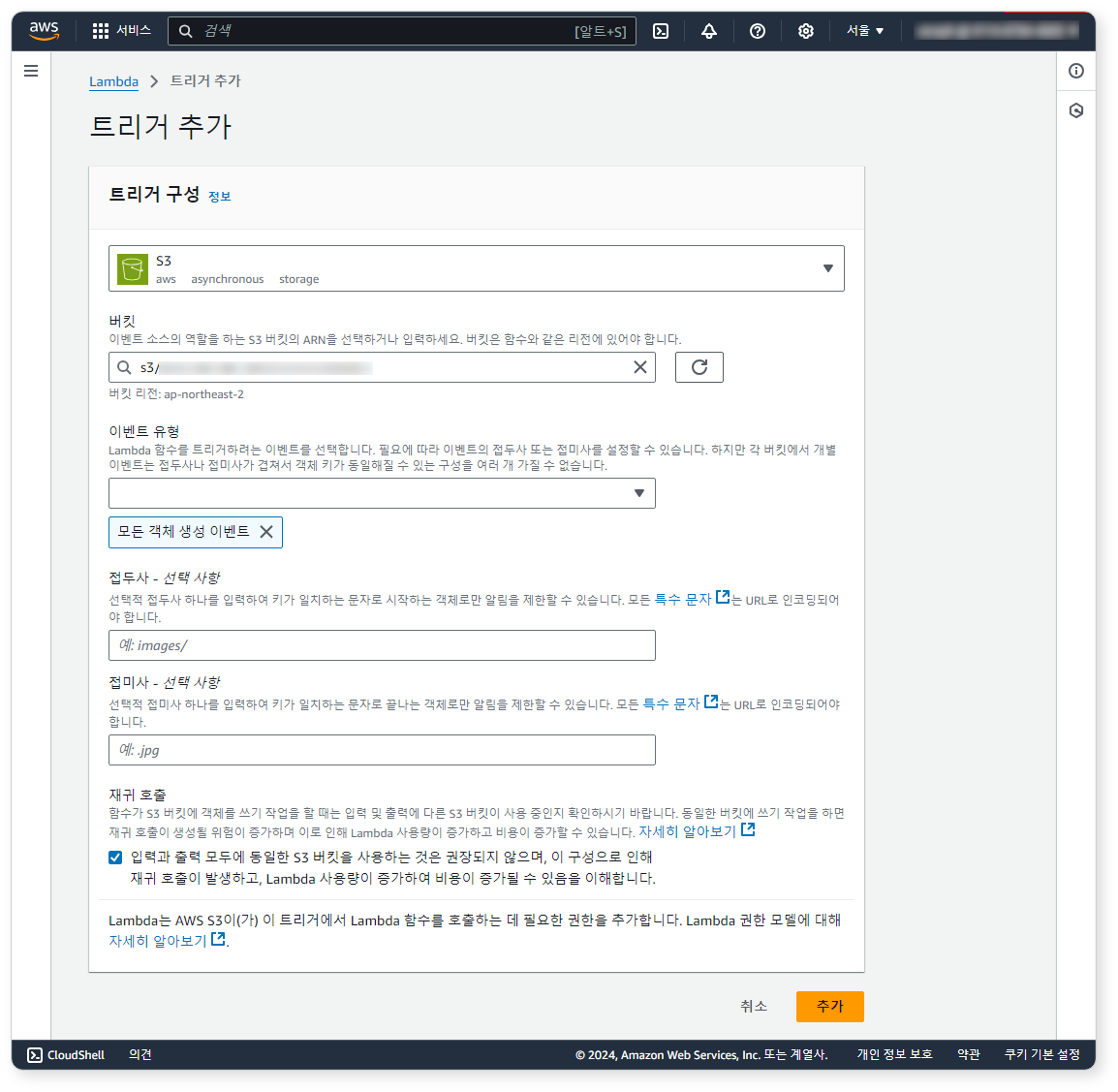
함수 개요 화면에서 트리거 추가 버튼을 클릭하세요.
-
트리거 추가 화면에서 S3 버킷을 선택하고 이벤트 유형으로 모든 객체 생성 이벤트를 선택하세요. 경고 문구가 나타나면 확인을 체크하고 추가 버튼을 클릭하세요.
동작 확인
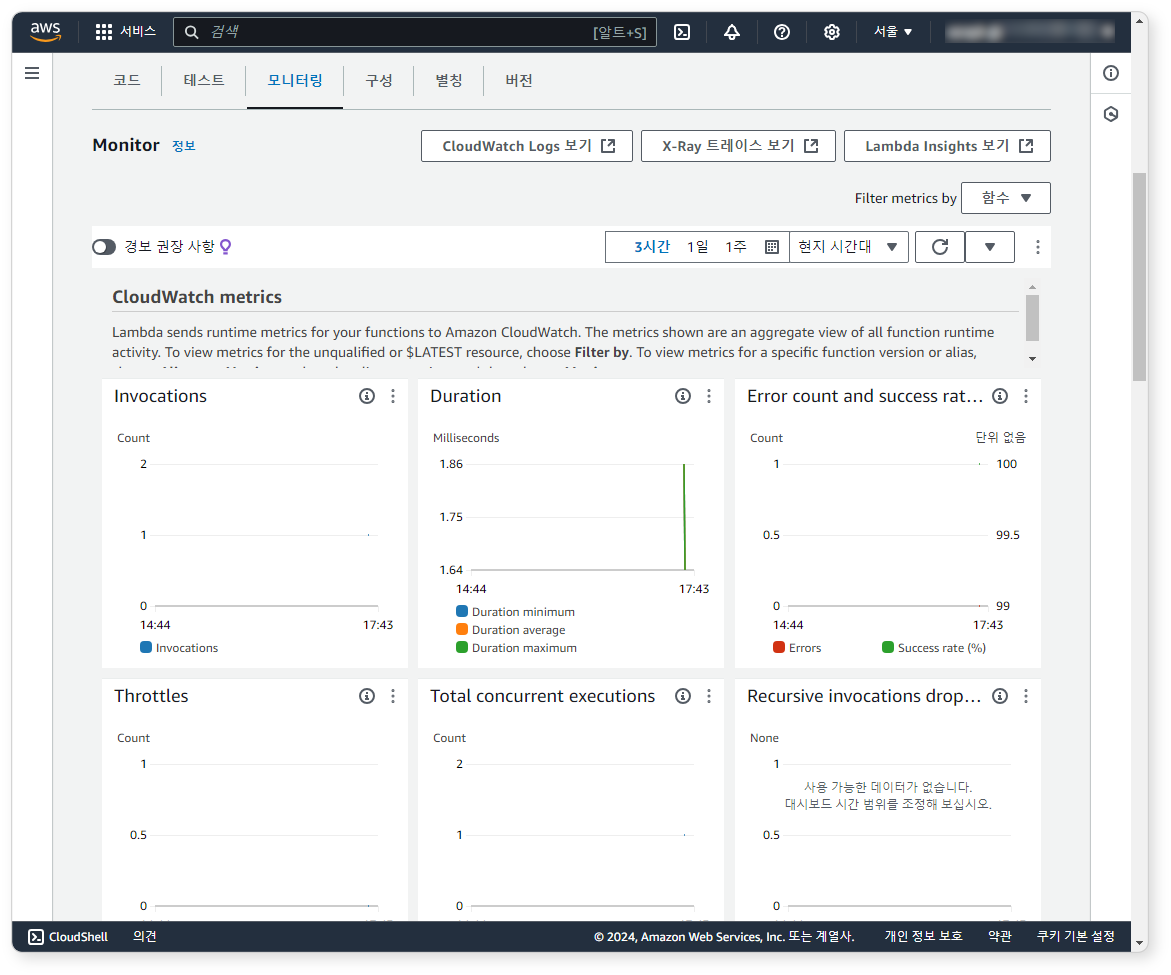
이제 모니터링 탭 화면에서 S3에 로그가 쌓일 때마다 Lambda 함수가 호출되는지 확인하세요.
로그프레소 수집 설정
AWS 앱을 설치하여 실행하고 설정의 접속 프로파일 메뉴로 이동합니다.
접속 프로파일
이 문서를 참고해 접속 프로파일을 추가하세요.
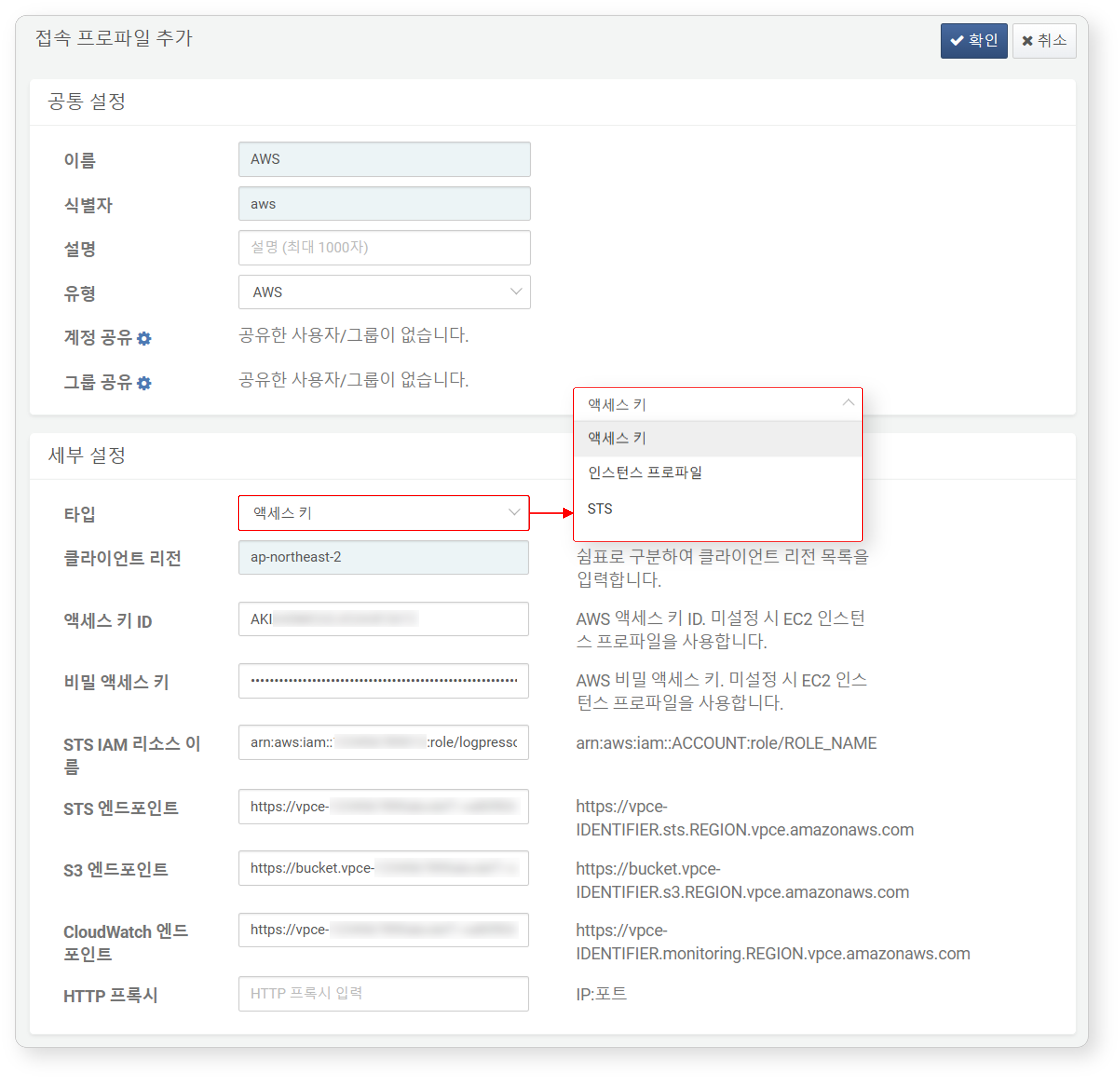
다음은 접속 프로파일 설정 중 필수 입력 항목입니다.
- 이름: 접속 프로파일을 식별할 고유한 이름
- 식별자: 로그프레소 쿼리 등에서 사용할 접속 프로파일의 고유 식별자
- 유형:
AWS선택 - 타입: AWS API 호출할 때 사용할 접근 키의 종류 선택(기본값: 액세스 키)
- 액세스 키: IAM 계정에 발급한 액세스 키와 비밀 액세스 키를 사용해 AWS API 호출
- 인스턴스 프로파일: 로그프레소 소나가 EC2 인스턴스에서 동작할 때, 인스턴스 프로파일 권한을 사용해 AWS API 호출
- STS: IAM 역할에 따라 AWS API 호출
- 클라이언트 리전:
ap-northeast-2등 API 접속을 허용할 리전을 쉼표(,)로 구분하여 입력 - 액세스 키 ID: (타입이 액세스 키, STS일 때 필수) IAM 사용자 추가 단계에서 복사한 액세스 키 ID(
AKIA로 시작) - 비밀 액세스 키: (타입이 액세스 키일 때 필수) IAM 사용자 추가 단계에서 복사한 암호
- STS IAM 리소스 이름: (타입이 STS일 때 필수) STS의 ARN 문자열 입력
- STS 엔드포인트: (PrivatefLink를 이용할 때 필수) STS 엔드포인트 URL
- S3 엔드포인트: (PrivatefLink를 이용할 때 필수) S3 엔드포인트 URL
- CloudWatch 엔드포인트: (PrivatefLink를 이용할 때 필수) CloudWatch 엔드포인트 URL
접속 프로파일을 생성하면 확장 명령어를 사용할 수 있습니다.
AWS CloudTrail 로그 수집 설정
이 문서를 참고해 수집기를 추가하세요. 로그를 암호화하려면 시스템 > 테이블에서 암호화가 적용된 테이블을 먼저 생성해야 합니다.
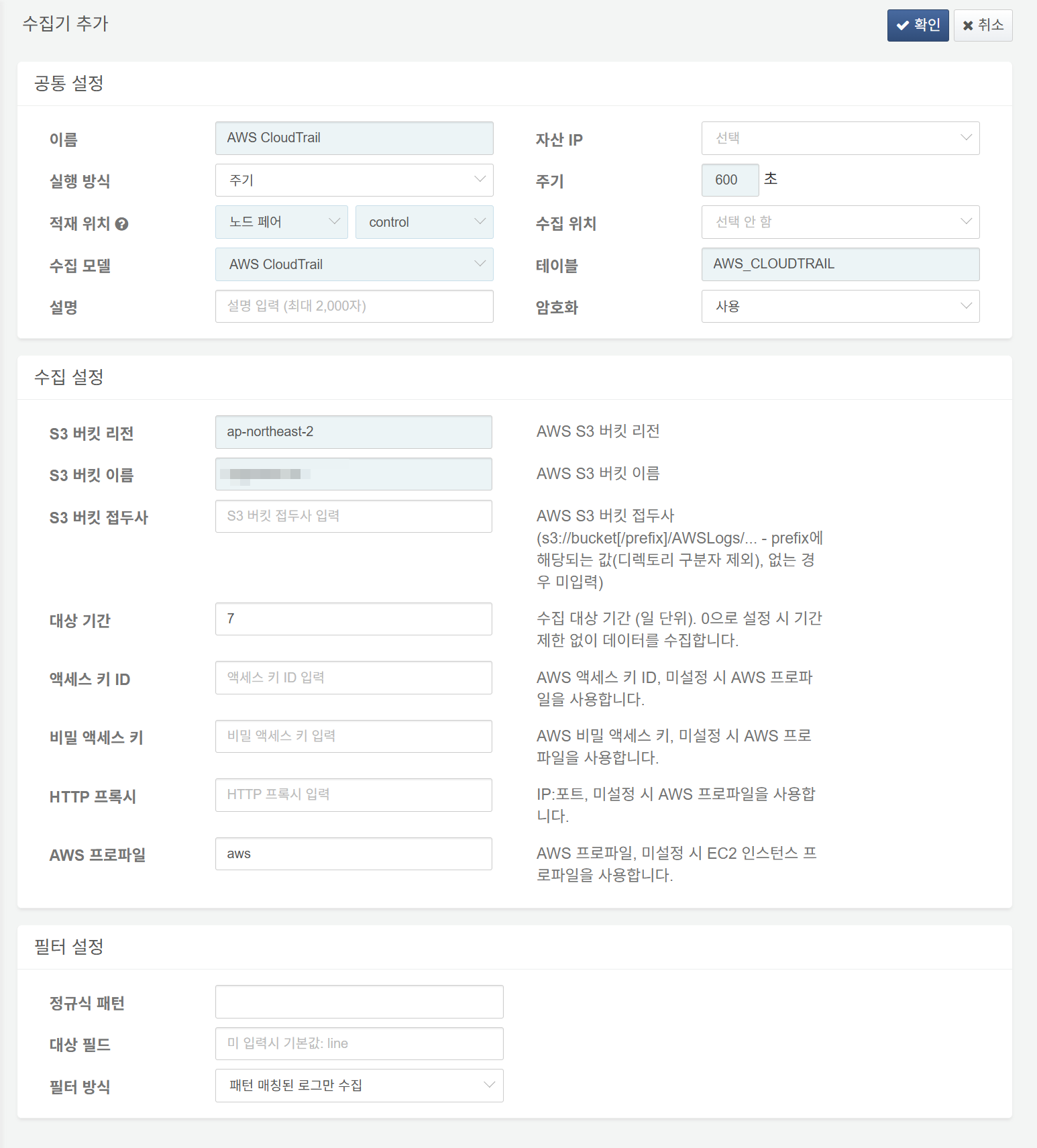
다음은 필수 입력 항목입니다.
- 이름: 수집기를 식별할 고유한 이름
- 주기: 600초
- 적재 위치/수집 위치: 로그프레소 플랫폼 구성에 따라 적합한 노드 선택
- 수집 모델:
AWS CloudTrail선택 - 테이블:
AWS_CLOUDTRAIL로 시작하는 이름 입력 - S3 버킷 리전: AWS CloudTrail 로그를 저장한 S3 버킷이 속한 리전
- S3 버킷 이름: AWS CloudTrail 로그를 저장한 S3 버킷 이름
- 대상 기간: 수집 대상 로그의 기간 범위(기본값: 0)
- AWS 프로파일: AWS 접속 프로파일 이름
AWS GuardDuty 로그 수집 설정
GuardDuty 콘솔에서 결과 내보내기 옵션을 선택한 다음 S3에 로그를 저장하도록 구성할 수 있습니다. AWS GuardDuty 수집기는 S3 버킷에 저장된 로그를 수집합니다.
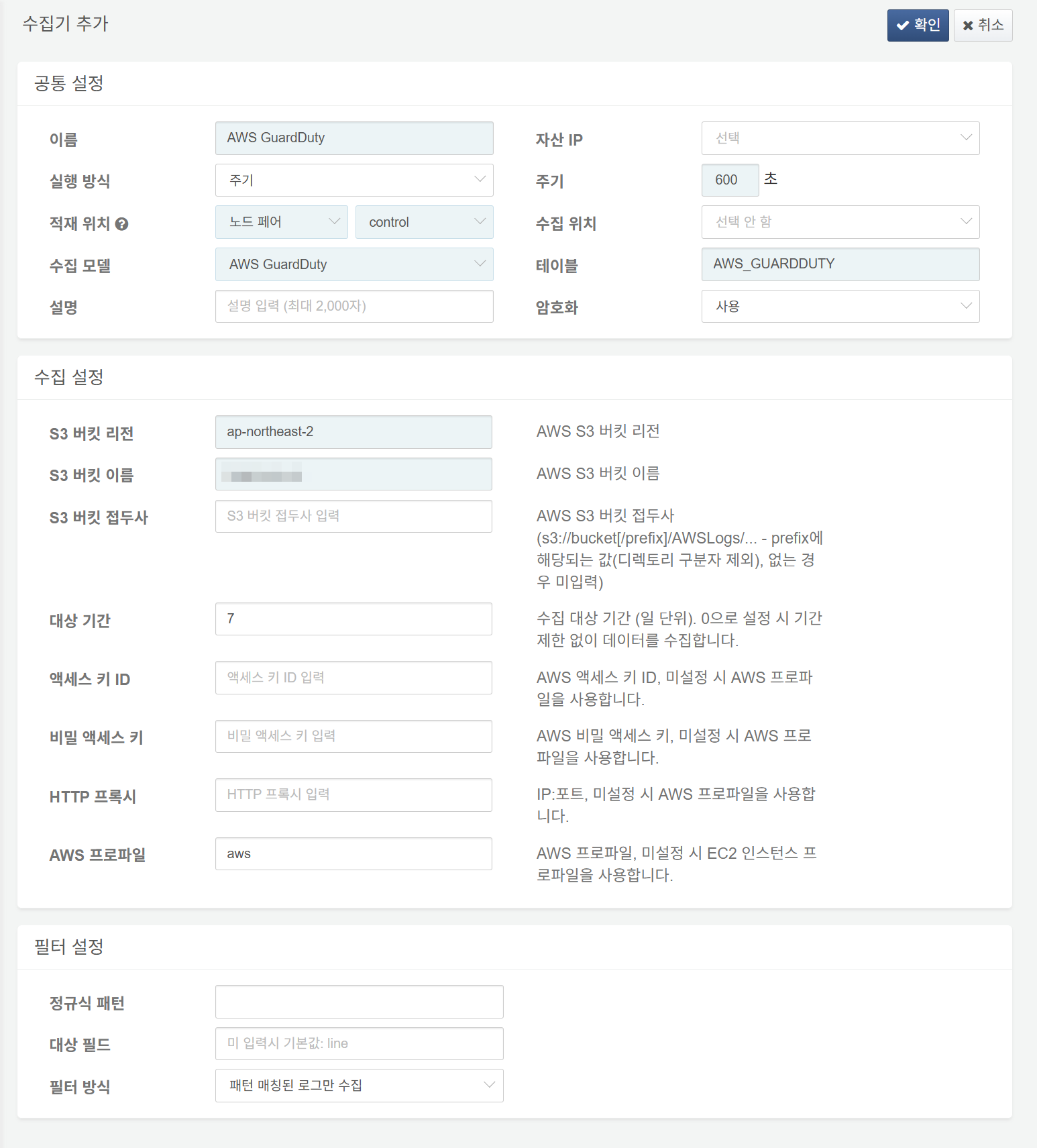
다음은 필수 입력 항목입니다.
- 이름: 수집기를 식별할 고유한 이름
- 주기: 600초
- 적재 위치/수집 위치: 로그프레소 플랫폼 구성에 따라 적합한 노드 선택
- 수집 모델:
AWS GuardDuty선택 - 테이블:
AWS_GuardDuty로 시작하는 이름 입력 - S3 버킷 리전: AWS GuardDuty 로그를 저장한 S3 버킷이 속한 리전
- S3 버킷 이름: AWS GuardDuty 로그를 저장한 S3 버킷 이름
- 대상 기간: 수집 대상 로그의 기간 범위(기본값: 0)
- AWS 프로파일: AWS 접속 프로파일 이름
AWS WAF 로그 수집 설정
먼저 AWS WAF 콘솔에서 Web ACLs > Logging and metrics로 이동하여 S3 버킷에 로그를 기록하도록 설정하세요.
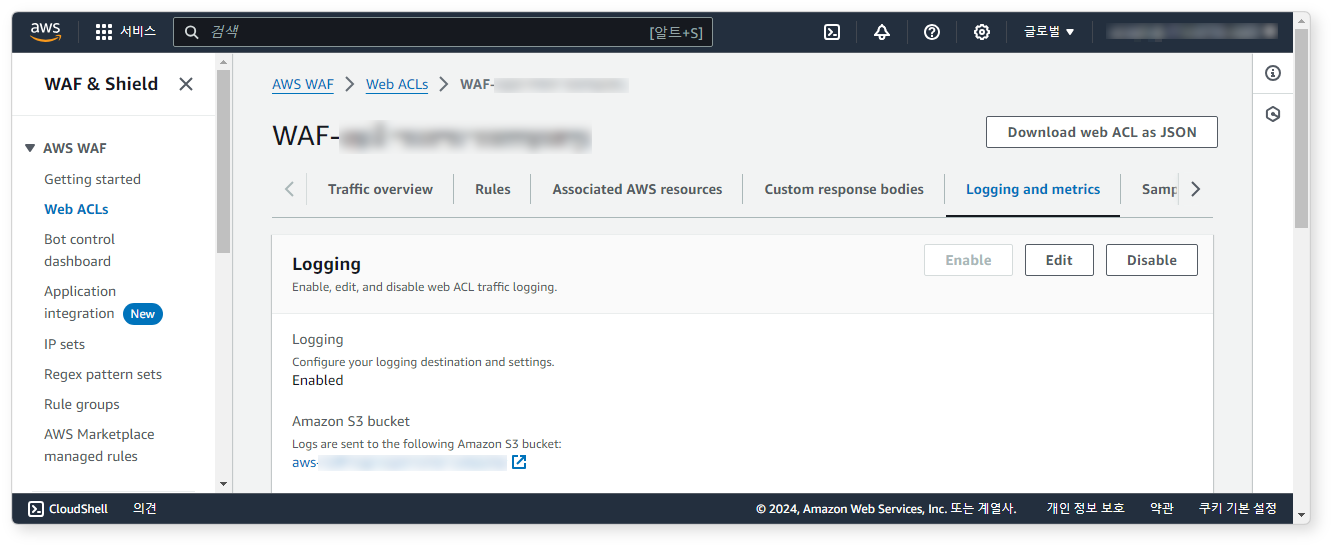
이 문서를 참고해 수집기를 추가하세요.
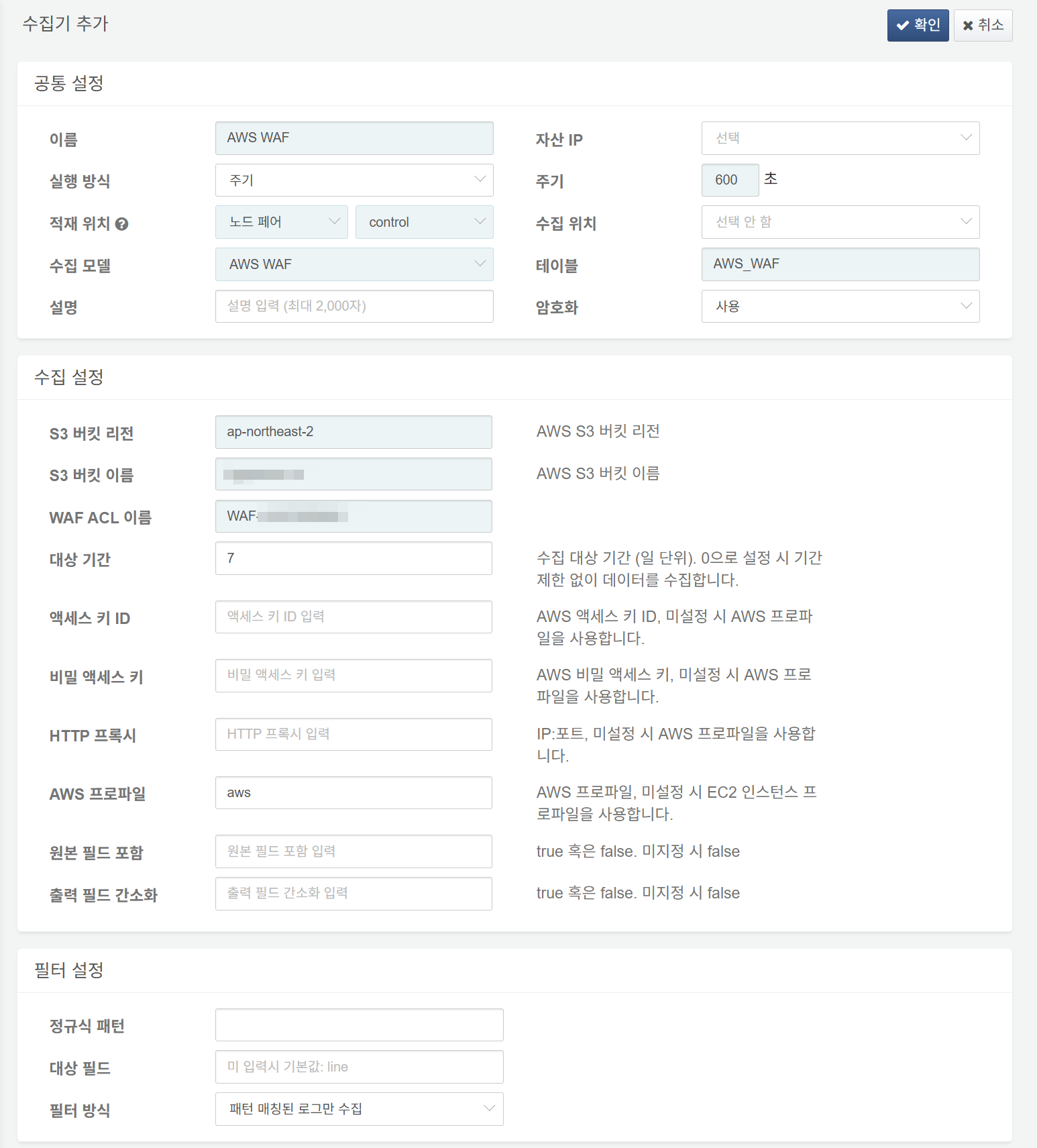
다음은 필수 입력 항목입니다.
- 이름: 수집기를 식별할 고유한 이름
- 주기: 600초
- 적재 위치/수집 위치: 로그프레소 플랫폼 구성에 따라 적합한 노드 선택
- 수집 모델:
AWS WAF선택 - 테이블:
AWS_WAF로 시작하는 이름 입력 - S3 버킷 리전: AWS WAF 로그를 저장한 S3 버킷이 속한 리전
- S3 버킷 이름: AWS WAF 로그를 저장한 S3 버킷 이름
- WAF ACL 이름: 웹 액세스 제어 목록 이름
- 대상 기간: 수집 대상 로그의 기간 범위(기본값: 0)
- AWS 프로파일: AWS 접속 프로파일 이름
AWS Shield 로그 수집 설정
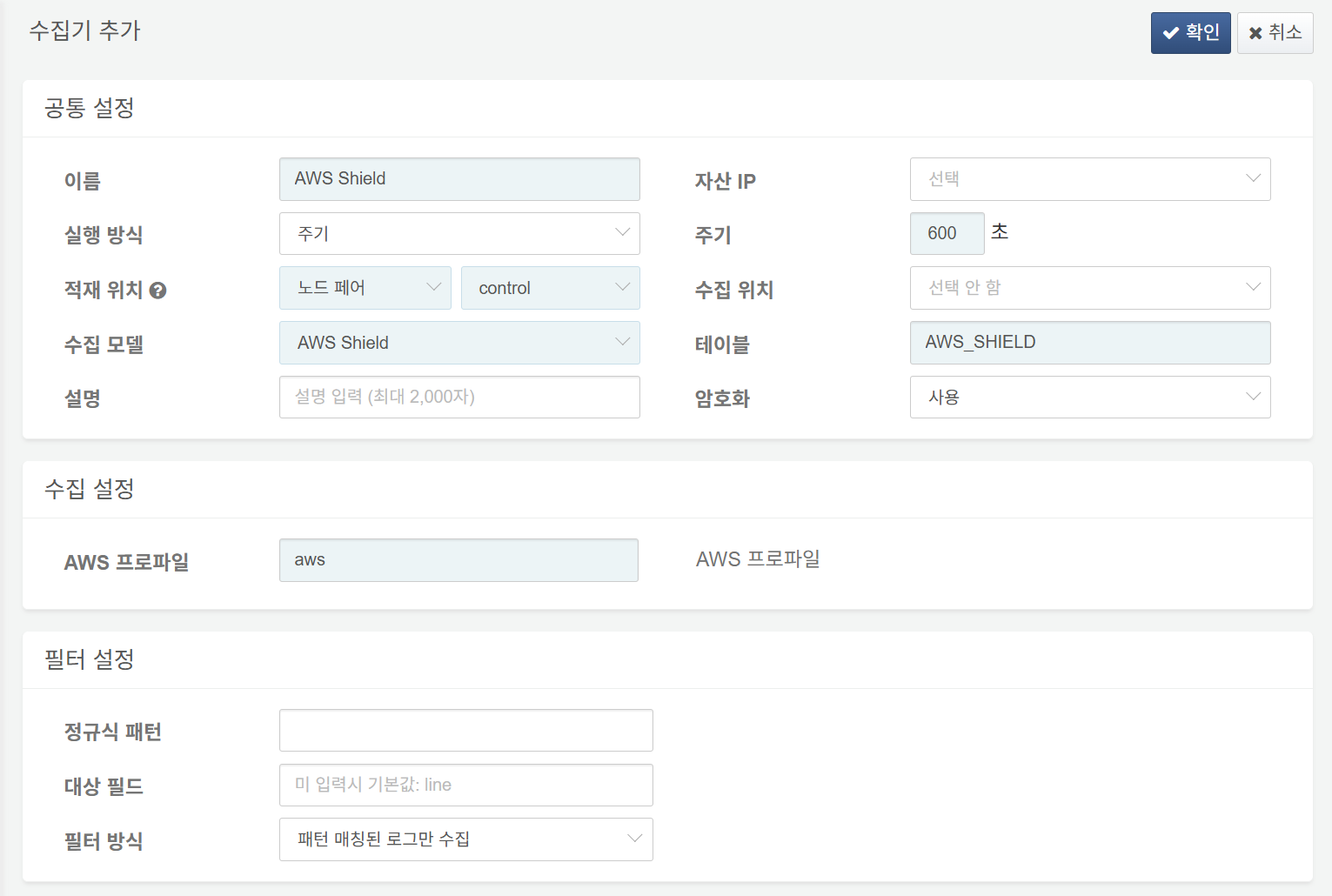
다음은 필수 입력 항목입니다.
- 이름: 수집기를 식별할 고유한 이름
- 주기: 600초
- 적재 위치/수집 위치: 로그프레소 플랫폼 구성에 따라 적합한 노드 선택
- 수집 모델:
AWS Shield선택 - 테이블:
AWS_SHIELD로 시작하는 이름 입력 - AWS 프로파일: AWS 접속 프로파일 이름
AWS ALB 로그 수집 설정
AWS 로드밸런서의 속성 탭에서 액세스 로그를 활성화하고 S3 버킷에 저장할 수 있습니다. AWS ALB 수집기는 S3 버킷에 저장된 액세스 로그를 수집합니다.
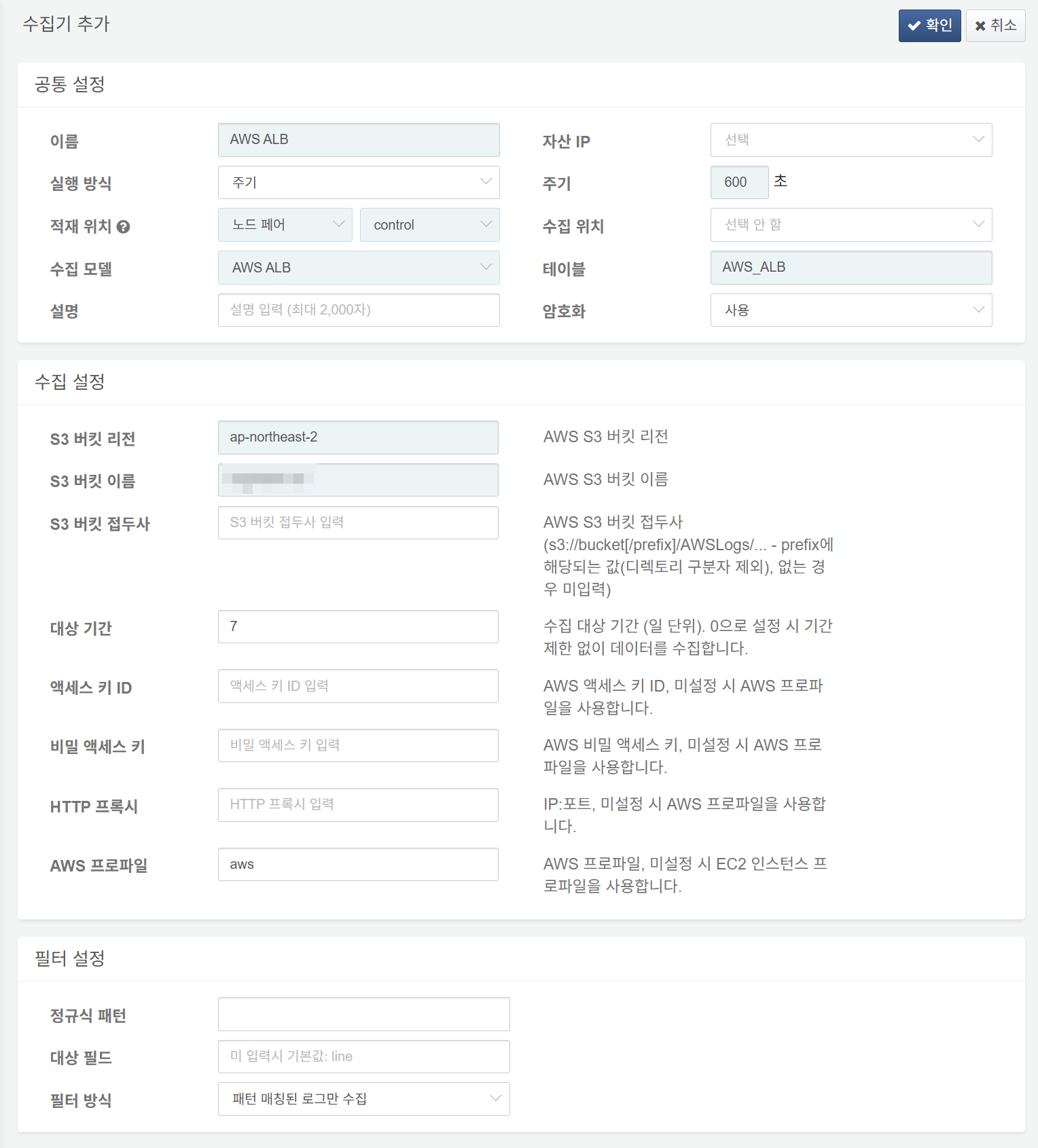
다음은 필수 입력 항목입니다.
- 이름: 수집기를 식별할 고유한 이름
- 주기: 600초
- 적재 위치/수집 위치: 로그프레소 플랫폼 구성에 따라 적합한 노드 선택
- 수집 모델:
AWS ALB선택 - 테이블:
AWS_ALB로 시작하는 이름 입력 - S3 버킷 리전: AWS ALB 로그를 저장한 S3 버킷이 속한 리전
- S3 버킷 이름: AWS ALB 로그를 저장한 S3 버킷 이름
- 대상 기간: 수집 대상 로그의 기간 범위(기본값: 0)
- AWS 프로파일: AWS 접속 프로파일 이름
AWS Aurora DB 로그 수집 설정
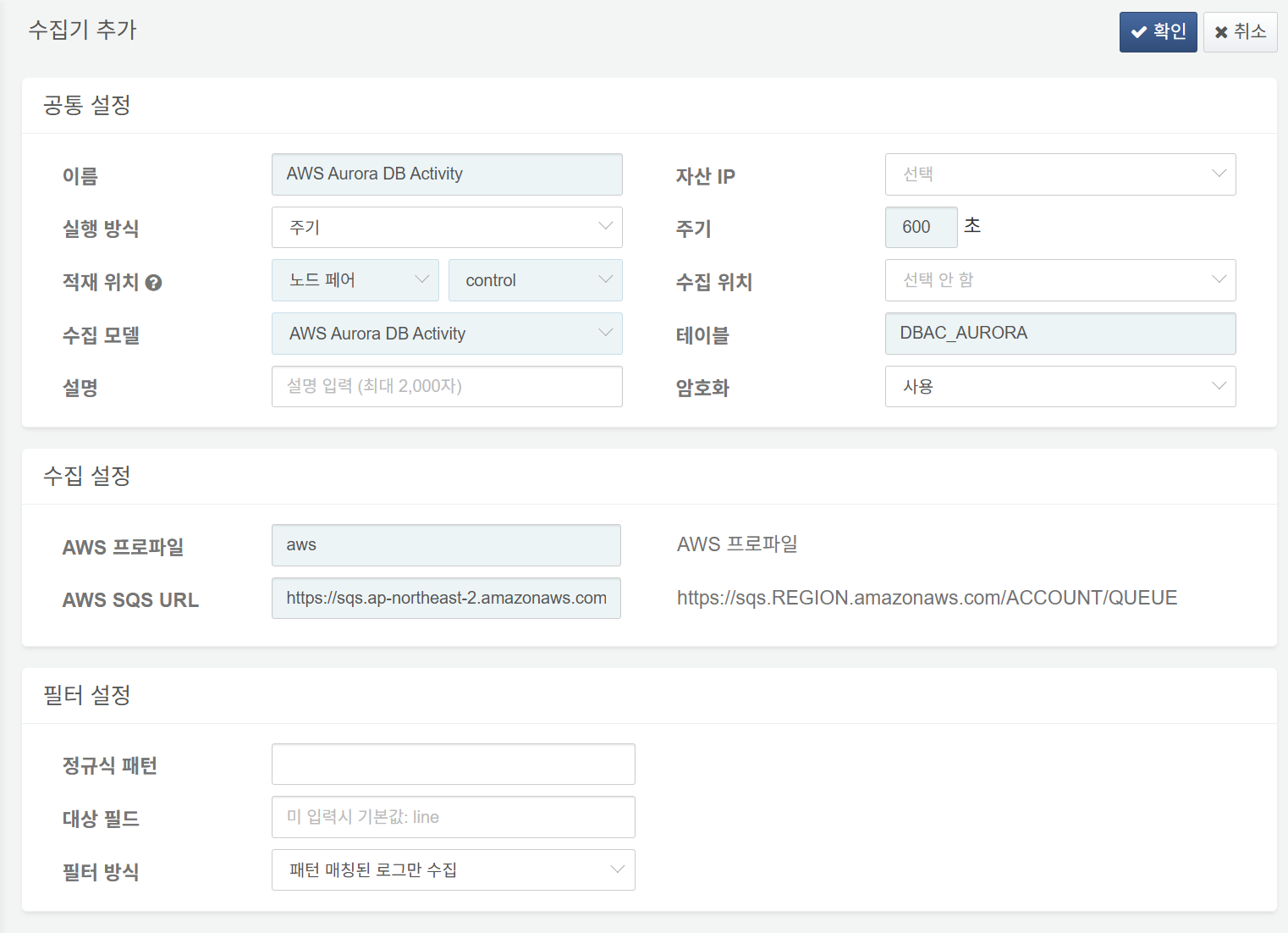
다음은 필수 입력 항목입니다.
- 이름: 수집기를 식별할 고유한 이름
- 주기: 600초
- 적재 위치/수집 위치: 로그프레소 플랫폼 구성에 따라 적합한 노드 선택
- 수집 모델:
AWS Aurora DB Activity선택 - 테이블:
DBAC_AURORA로 시작하는 이름 입력 - AWS 프로파일: AWS 접속 프로파일 이름
- AWS SQS URL: AWS SQS의 엔드포인트 URL 입력(예:
https://sqs.ap-northeast-2.amazonaws.com/ACCOUNT_ID/logpresso-aws-aurora-das.fifo)
AWS S3 Daily Rolling Directory Watcher 로그 수집 설정

AWS S3 일자별 디렉터리 수집기를 생성하기 위해서는 수집 모델 추가가 필요합니다. AWS S3 일자별 디렉터리 수집은 AWS 1.6.2501.0 버전부터 지원합니다.
- 이름: 수집 모델을 식별할 고유한 이름
- 유형:
AWS S3 Daily Rolling Directory Watcher선택 - 정규화 규칙:
원본기본 선택 (자세한 내용은 수집 모델을 참고하세요.)

다음은 필수 입력 항목입니다.
- 이름: 수집기를 식별할 고유한 이름
- 주기: 600초
- 적재 위치/수집 위치: 로그프레소 플랫폼 구성에 따라 적합한 노드 선택
- 수집 모델:
위에서 생성한 수집 모델선택 - 테이블: 로그를 저장할 테이블 이름 입력
- AWS 프로파일: AWS 접속 프로파일 이름
- S3 버킷 리전: 수집할 로그가 저장된 AWS S3 버킷이 속한 리전
- S3 버킷 이름: 수집할 로그가 저장된 AWS S3 버킷 이름
- 대상 정규표현식: 수집 대상 S3 객체 이름을 검증할 정규표현식
- 날짜 포맷: S3 객체 이름에서 날짜를 파싱하는데 사용할 포맷(미설정 시 yyyy/MM/dd를 기본값으로 사용)
멀티 라인을 로그를 수집하거나 수집 대상 기간을 지정할 경우 아래 선택 항목을 입력합니다. 로그 시작/끝 정규표현식 옵션 및 날짜 정규표현식 옵션은 AWS 1.7.2504.0 버전부터 지원합니다.
- 날짜 정규표현식: 날짜 및 시각을 추출하는데 사용할 정규표현식
- 로그 시작 정규표현식: 새 로그의 시작을 인식하기 위한 정규식(멀티 라인 로그 수집 시 사용)
- 로그 끝 정규표현식: 로그의 끝을 인식하기 위한 정규식(멀티 라인 로그 수집 시 사용)
- 대상 기간: 수집 대상 로그의 기간 범위(일 단위)
마무리
이제 모든 설치 작업이 완료되었습니다. 수집 메뉴에서 데이터가 잘 수집되는지 확인하고, 대시보드로 이동하세요!